 |
||||
| Dette produkt er udgået. Vi henviser i stedet til Ret Mig og Kommaforslag. | ||||
 |
|
|
Sproglige ResurserKontekstfrie resurser og leksikografiListekontrol og kompositaRygraden i de fleste traditionelle stavekontrolprogrammer består af en liste af i normsproget accepterede ordformer. Et standardprogram vil ganske enkelt definere en fejl som et ord der ikke figurerer på listen. For dansk kan denne metode medføre mange falsk positive fejlmeldinger, fordi sproget forholdsvis frit sammensætter nye komposita, og OrdRet har derfor dels inddraget tekstkorpora til at opbygge et leksikon med sjældne komposita, dels indbygget en morfologisk analyse, der kan genkende ukendte ord som mulige komposita snarere end ”røde” fejl . Et andet problem med en ren listekontrol er, at listen vil acceptere de to dele af (forkert) særskrevne ord hver for sig, ja ofte ligefrem tilskynde brugeren til at bryde komposita i to udelukkende for at ”tilfredsstille stavekontrollen”. Her vil OrdRet benytte sin viden om komposita, samt morfologisk interdependente træk i nabo-ord, til at markere særskrivningsfejl (fx ’banegårds center’).FejldatabaserSom tidligere nævnt, udmærker OrdRet sig ved at supplere korrekt-listen med en data-dreven fejl-liste , der genkender fejlstavede ord direkte og sammenholder dem med de forskellige ord, fejlen er blevet rettet til i database-teksterne. Imidlertid har det været umuligt at finde materiale nok til at dække hele sproget og gennemføre en dækkende fejlstatistik. For at sikre at alle rimelige rettelsesforslag kom med for en given fejl, skulle fejllisten derfor gennemgås manuelt, især for korte ord, hvor små ændringer skaber potentiel lighed med mange andre ord i sproget. Desuden anvendes der en liste over fejlmønstre i ordstammer med variable dele. Den empiriske fejldatabase indeholder over 13.000 opslag, den manuelle godt 5.000.OrdlighedFor alle andre end de allerbedste stavere er det et gode, at en stavekontrol ikke bare markerer mulige fejl, men også foreslår rettelser udfra hvilke ord, der ligner det fejlstavede ord mest. Sammenligningsalgoritmerne skal optimeres, fordi det ikke indenfor rimelig tid er muligt at foretage en dybdegående sammenligning med alle over 1 million ordformer i OrdRets database, og vi har derfor genereret specialleksika, der arbejder med ”alternative” ordbilleder: Fonetisk transskription, ordstammer, konsonant- og vokalskeletter m.m. Specielt ordblinde laver mange lydligt baserede fejl, og vi har således udviklet en transskriptionsmaskine, der kan gætte udtalen af et fejlstavet ord og sammenligne det med transskriptionerne af eksisterende ord.ForslagsprioriteringFor dårlige stavere, der ikke har en sikker genkendelse af korrektstavede ord heller, er det afgørende ikke kun at finde et antal lignende ord, men også at foretage en god prioritering, optimalt med det rigtige forslag på plads 1 eller 2. OrdRets lighedsvægtning inddrager hele sætningskonteksten til en sådan prioritering (se side 18), fordi selv ord, der ellers ligner meget, kan være meningsløse i konteksten. Lokalt bygger vægtningen på 3 søjler – grafisk lighed, fonetisk lighed og ordets frekvens i normalsproget. Som udgangspunkt for sidstnævnte har vi i projektet kompileret en logaritmisk vægtet frekvensordbog.Fejl i korrektstavede ordEt stort problem for en traditionel, listebaseret stavekontrol er at også ellers korrektstavede ord kan være forkerte – enten (1) fordi et fejlstavet ord tilfældigt kommer til at ligne et andet, eksisterende ord (mere sandsynligt, når især ordblinde brugere laver mere end én fejl pr. ord), eller (2) fordi fejlen er rent grammatisk, stilistisk, eller ordstillingsrelateret. OrdRet markerer grammatiske fejl (2) vha. kontekstbaserede regler (”grønne” fejl), mens den håndterer (1) ved at optage også korrektstavede ord i fejllisten som potentielle fejl, og råder i øvrigt over et stort homofonleksikon, der kan bruges til at udpege mulige forvekslinger. Imidlertid er der en reel risiko for falsk positive markeringer ved denne metode, og den stiller store krav til OrdRets kontekstuelle disambiguering, som gennemgås i næste afsnit.Grammatiske, kontekstbaserede resurserKongstanken i OrdRets modulære arkitektur har været at benytte og tilpasse en eksisterende dansk Constraint Grammar parser (DanGram) for kontekstuelt at prioritere (vælge/forkaste) rettelsesforslag. På niveau 1 bliver alle ord i en sætning, plus rettelsesforslagene, fodret ind i DanGrams morfologiske tagger, der opmærker ord med mulige læsninger som fx navneord i flertal nominativ, eller udsagnsord i datid. Ord med rettelsesforslag får tildelt summen af alle læsninger for både ordet selv og alle dets rettelsesforslag. DanGram anvender herefter en sprogteknologisk grammatik (2.550 regler) til at bedømme, om en given læsning er lovlig i konteksten eller ikke. Fx kan en læsning som udsagnsord favoriseres, hvis der står et navneord i bestemt form til venstre, mens udsagnsord forbydes til højre for kendeord og bindeord . Grammatikken er i projektet blevet udvidet med flere regelsæt (800 regler), der håndterer den øgede flertydighed rettelsesforslagene medfører, samt kan forholde sig til OrdRets egen opmærkning (grafisk og fonetisk lighed, listeprioritering, frekvensklasser m.m.)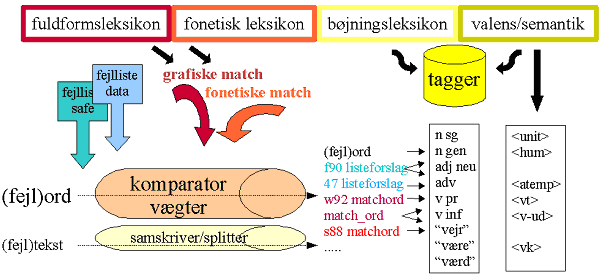 Figur 5: Komparator og tagger Figur 6 viser samspillet mellem på den ene side den leksikondrevne ”komparator”, der finder fejl og vægter rettelsesforslag vha. leksikalske resurser (fuldformsleksikon, fonetisk leksikon, bøjningsleksikon og fejldatalister), og på den anden side taggeren, der fastslår ords grundformer (fx ”være” for ”er”, ”var”, ”været” etc.), tilføjer morfologiske læsninger (fx n=navneord, sg=singularis). Tallene viser de indbyrdes vægtninger (fx w92=best written match, s88=best spoken match). Til brug ved den kontekstuelle disambiguering tilføjes også oplysninger om relationer imellem ord (fx <vt> for ’transitivt udsagnsord’) og semantiske klasser (fx <hum> for ’menneskeord’ og <atemp> for tidsbiord). De grammatiske regler kan ikke kun prioritere eksisterende rettelsesforslag, men også selv tilføje ny information, vha. såkaldte mapping-regler (jf. Figur 6). Disse regler kan fx ”mappe” kontekstafhængige rettelsesforslag (@:forslag), samskrivninger (@comp) eller identificere umarkerede sætningsgrænser (manglende punktum: @headstop). 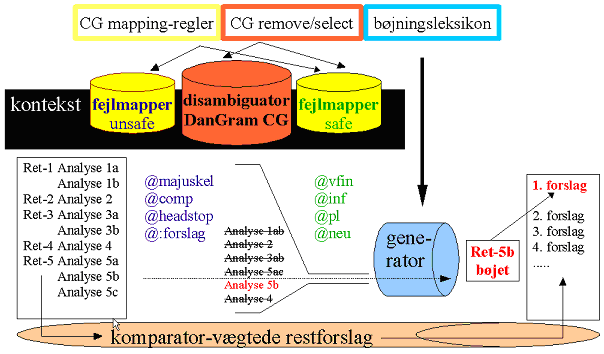 Figur 6: Mapping-regler i OrdRet På niveau 2 forsøger OrdRets Constraint Grammar-modul at finde grammatiske fejl (grøn i illustrationen), der mappes også på ellers korrektstavede ord. Blandt de vigtigste genkendte fejltyper er kongruensfejl (tal og køn), samt forvekslingen mellem udsagnsords grundform (’-e’, @inf) og den nutidsbøjede form (’-er’, @vfin). Nedenstående vises en række eksempler for mapning af @-fejltyper, samt en kort omskrivning af de anvendte kontekstbetingelser (kursiv). Hun har en opfattelse af at kvinde (@pl) er bedre til det merster (R:meste). (ingen indefinitte entals-substantiver uden prænominaler, - undtagen <mass>) Han kan ikke hører (@inf) dig. (hjælpeverbumskontekst) Han ønsker ikke og (@:at) forstyrre. (verbum med infinitivvalens til venstre, infinitiv til højre) Hun besøgte barndoms (@comp-) veninden. (ubestemt substantiv i genitiv ental før et substantiv i bestemt form) Glasset var fuld (@sc-neu). (kongruenskrav mellem subjekt og subjektsprædikativ) Jeg er træt (@headstop) Det har vært (R:været) en lang dag. (Majuskel og/eller syntaktiske tegn på starten af en ny sætning) (tillægsmåde 'været' vinder over navneordet 'vært' pga. hjælpeverbum tv.) I alt genkender OrdRet over 40 forskellige grammatiske fejltyper. Fordi konsortiet vurderede, at målgruppen ikke ville kunne omsætte denne slags abstrakt fejltypemarkering til egentlige rettelser, blev der udviklet en såkaldt morfologisk generator, der konstruerer de nye, korrigerede bøjningsformer, og indsætter dem på forslagslisten i stil med de forslag, der stammer fra komparatorens leksikalske sammenligninger. Denne side er taget fra rapporten, som er tilgængelig i PDF format: |
|
|
Dette produkt er udgået. Vi henviser i stedet til Ret Mig og Kommaforslag. |
||||